Dissecting the Blackbox
Often regarded as a blackbox, the deep-learning neural networks are used as function estimators, trained using backprop. How can we “control” what does the neuron inside the blackbox learn? Ability to control the blackbox not during inference (although that is another fascinating subject as well) but during training?
Most of the times, we don’t care how our layers of neurons decide to learn to activate themselves as far as we get our desired accuracy from the model.
However, it gets interesting and challenging when the task at hand is hard enough to not give the “desired accuracy”, forcing us to deep dive in our trickery to get the best out of “the blackbox”:
- Hyperparameter tuning
- Getting the network architecture just right
- Pretraining and Finetuning for more knowledge of the world
- Ensembling
- Dissecting the loss function
- Dissecting the dataset
After trying combination of above, if it still doesn’t give the desired accuracy (although in most cases it would), then, we have to dissect the blackbox itself!
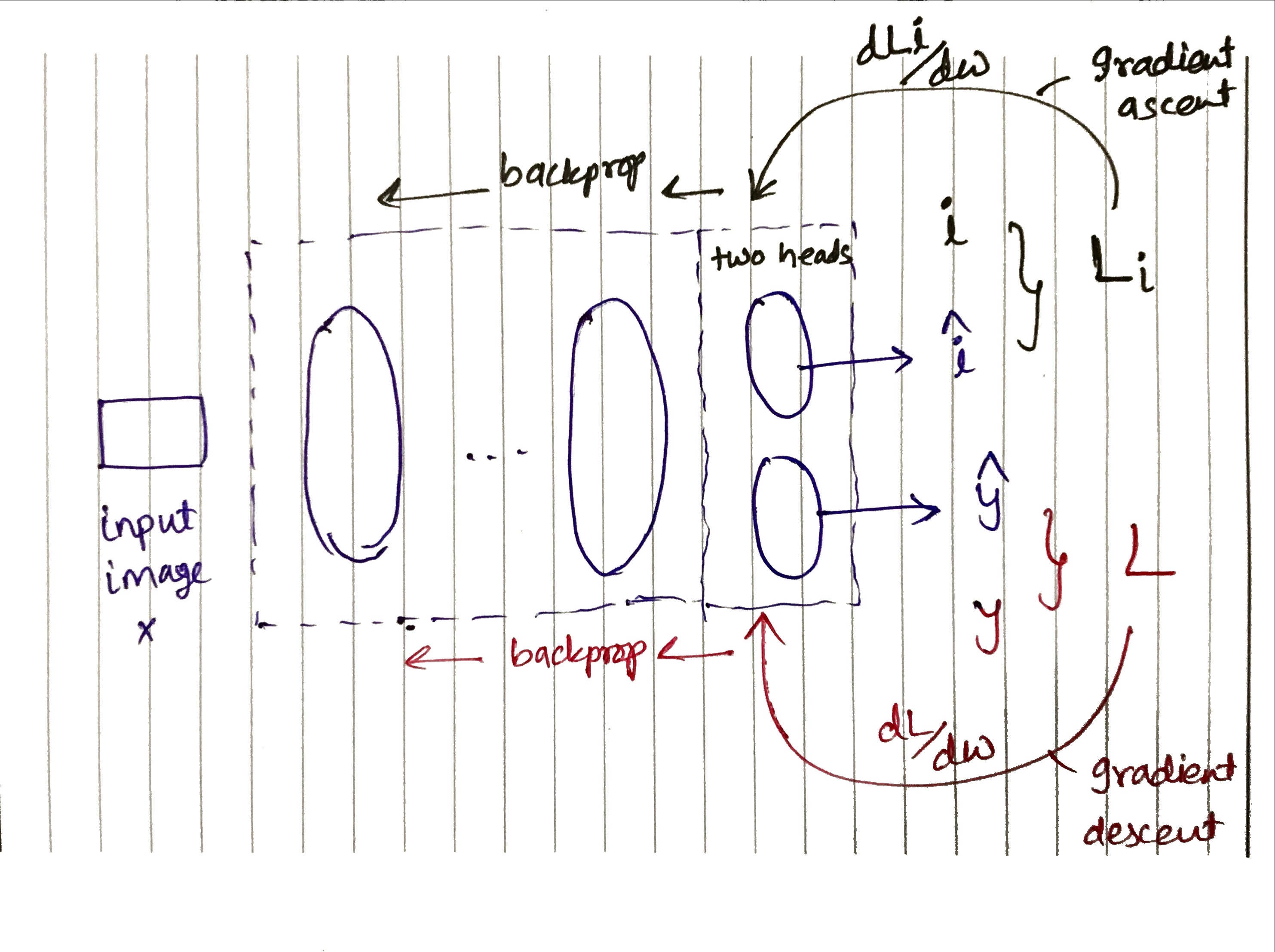
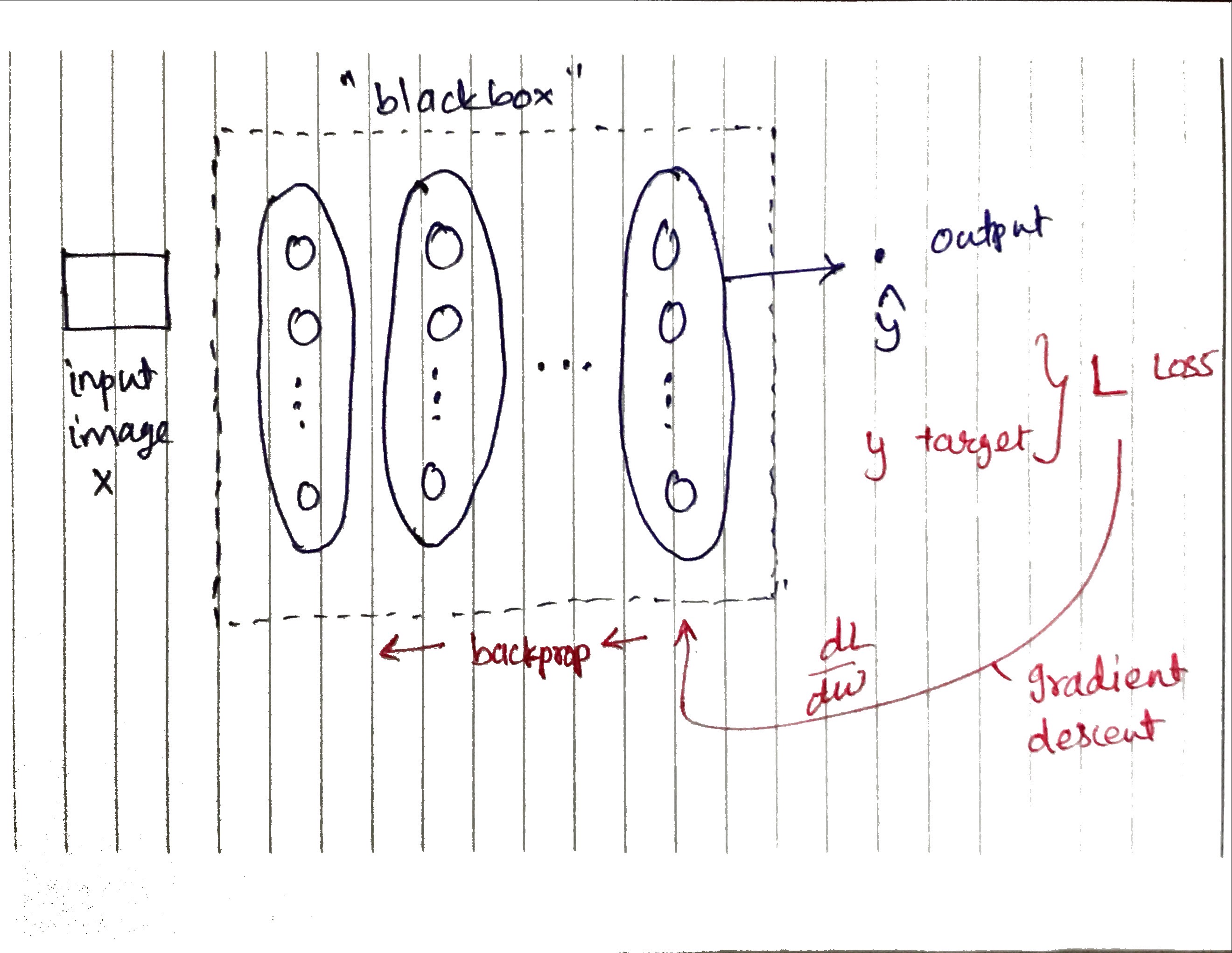
The Blackbox
Recap that our blackbox is made up of layers similar to this example from keras’s mnist example :
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
e
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
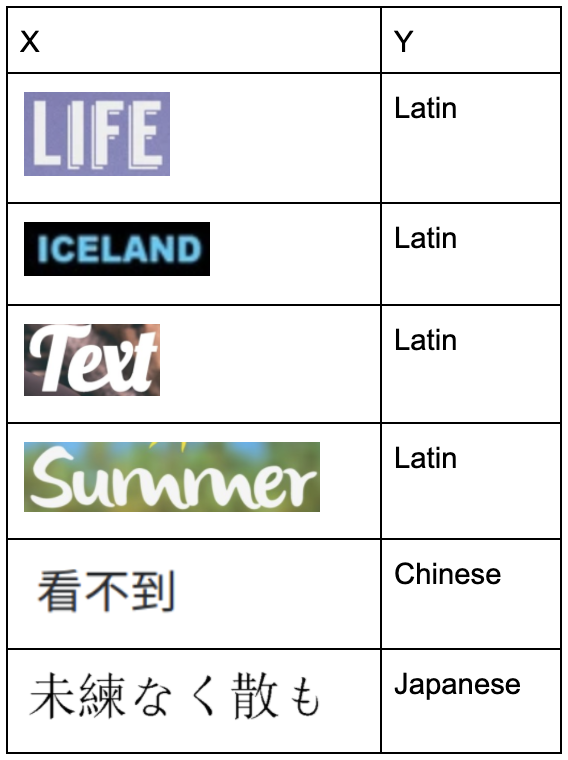
Dataset
Contrary to the MNIST task however, let say we want to classify script from the image with text. For example consider the input images as cropped regions who are confirmed to containing some text. (This can be thought of as a part of the bigger OCR pipeline of text recognition task from image.) The output is the script of the image text like latin, chinese, japanese, etc.
Training
Remember that generally, gradient descent would allow the network to learn the weights via back-propagation.
Learning
The initial layers of the big neural network learns edges, contours and shapes of the objects in the image. For our “script detection” task it would also learn the edges and curls of the text in the images in order to “read” the text!
Some layers might be “wasted” in learning the color and font-style of the image text! We want to control for layers to learn tasks only related to script detection.
Imagine that the accuracy we got after model optimizations for script detection task is ~70%, and we observe that for a particular font-style like “Caveat” the model makes mistakes! How do we make our script detection model invariant of font-style?
Multi Head Training
We already made the target y (dependent variable) be variant of the image content x (independent variable) using gradient descent. How do we make y invariant of font-style? Gradient Ascent.
Let’s have two heads for the last layer of the model, one head for the target y as usual, and other head would be used to predict font-style! We need font-style also tagged now in the original dataset.
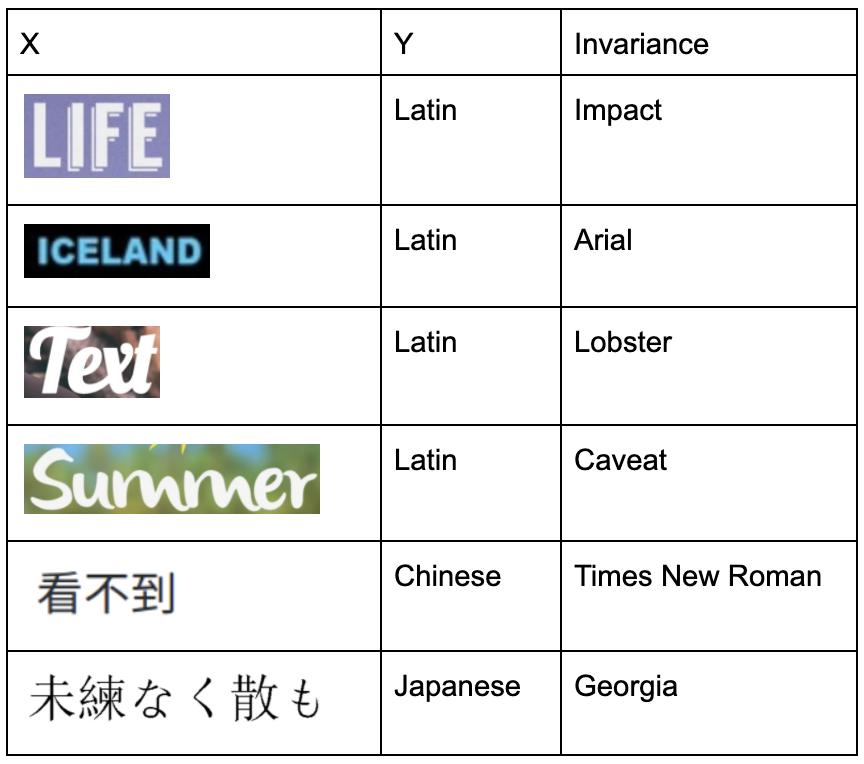
This additional information would allow us to modify our training to signal the layers not to be activated for font-style as that doesn’t affect which script the text is in. We want the model to “Unlearn” font-style.
The new invariant head is from where we would back-propagate weights with the gradient ascent, as we want model to give maximum invariant loss.