About Modeling Conversations using Neural Networks
Recently there has been a great push in AI for seq2seq models. You might associate these language models for the use of neural machine translation (NMT) & innovations for other language generation tasks like chatbots. But NMT and chatbots actually fall into the opposite spectrum of natural language generation tasks:
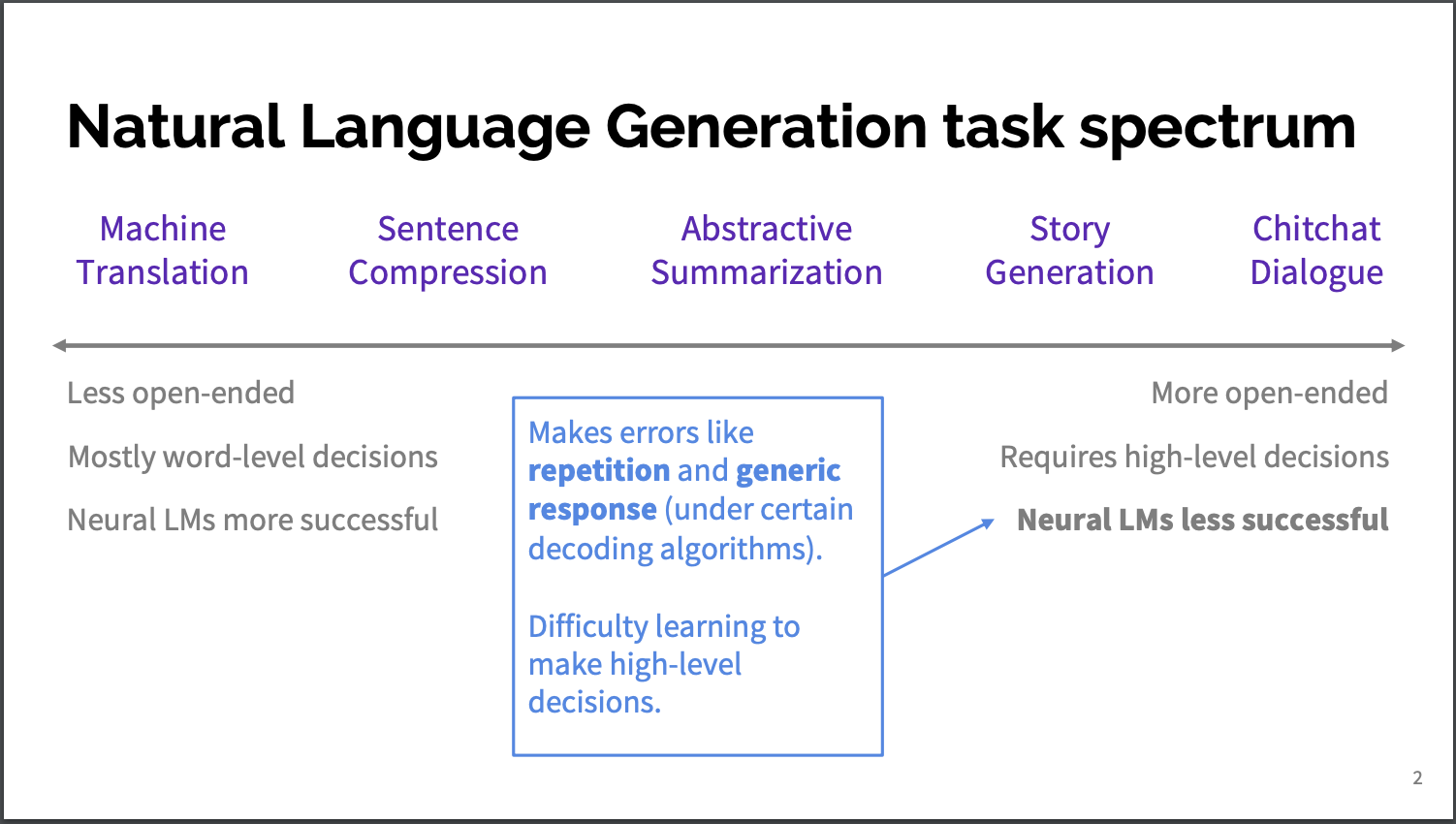
Are you trying to use seq2seq models for dialogue systems? i.e., encoder-decoder networks for chatbots/conversational AI? You need to be aware of the following nuances of natural language understanding before using the same networks to achieve your tasks which were originally meant to be used for machine translation.
This article only describes the common problems and needs faced in conversational AI “natural language generating” systems.
No solutions for them! As I guess chatbot which feels “human” is still an open problem in AI, also based on your choice of taste there can be different solutions for each of these problems. Amazon has an open challenge called AlexaPrize for $2.5M to advance some of these difficulties.
Natural Language Modeling
In NLP we use Language Models to understand the semantics of a language. Moreover, we try to acquire the validity of a sequence of words to contain meaning in a particular language. Technically, this is achieved by determining the probability of a sequence of words.
This post provides a nice overview of language models if you want.
These models can be viewed as just the “decoder” of our seq2seq models. In conversational AI tasks, the decoders not only learn the specific natural language we are interested in (let say English) but also the tasks specific voice, for e.g., if we are training a bot to answer support queries it also incorporates the agent’s voice from the training dataset. Rather it needs to do that in order to answer queries.
This requires a decoder to do more than language modeling and the field has naturally emerged to calling it natural language understanding. The traditional NMT network performs NLM, not quite the NLU as we want.
Natural Language Understanding
In seq2seq models, the encoders are used to capture additional details for task-specific language understanding.
You might have heard that the conversational AIs capture intents and entities for explicit language understanding. The encoders in seq2seq are another way to capture the features of the question. (and generate the answer for it.)
The chatbots today fail to achieve human-level answers. None the less, they are pretty close to repetitive tasks like answering support queries on a forum given large datasets. On top of intents and entities, they need to achieve the following for getting close to human abilities.
Context
In a natural conversation, humans remember the context. They use the language which reflects the natural tone of the flow. However, in most seq2seq models for chatbots, only the last message is used to predict the answer sequence. These models need to somehow incorporate the existing context as well.
The original “NMT models” didn’t have the need for this. Because in translation tasks there is no previous context. The query contains all the context there is. This requirement is unique to conversational systems.
Diversity (Repetition)
Even for the same questions, humans can react to them differently. For example, one can answer in sympathy and others can answer with the emotion of love in the exact same situation. And both answers will be valid.
This means in conversation systems there would be more than one correct way to form an answer for a given question (or conversation). This would add complexities and bias in any real-world conversational datasets if there were more parties involved. For e.g., if our support queries dataset is having answers from more than one agent and those agents tend to answer with different emotions we have an inherent bias in the training data.
However, this bias not that bad, because conversational AI also has to have the ability to general answers diversely, even for the same question, given the external emotion.
Because of this most conversational AI systems tend to have more than one suggestion for the answers. (Like, the smart responses suggestions from Gmail.)
Genericness (Specificity)
Sometimes “I don’t know” or “Thank You” becomes the swiss-army-knife for chatbot models. Because they work in most questions. But to get the human feel from conversational AI we need the AI to deliver the answers as specific as possible. In other words, it should remove the habit of answering generically for the question.
Network Requirements
Because of the above unique requirements, the vanilla encoder-decoder networks become limited to solve chatbots. On top of that, we have a few more task-specific technical difficulties for chatbots.
Lack of Evaluation Metric
Most encoder-decoder networks use BLEU score metric in training. While it works very well for machine translation tasks it isn’t ideal for question-answering tasks. And, I am afraid there doesn’t exist a complete evaluation metric yet for conversational tasks. (otherwise, this wouldn’t be an open problem)
More details about that can be found in this paper.
Need for Control
Most deep learning models work as a black box. And other than tuning architecture there isn’t much a data scientist can do to achieve the desired accuracy for the models. The ability to control the predictions based on external constraints is the real need for any deep learning model but it is more critical in conversation systems. For example, we want to control the emotion of the answer explained in Diversity.
There is still so much to achieve in making chatbots to be more human for state of the art. We can’t use vanilla encoder-decoder networks of NMT for bots and hope that it will have engagingness and won’t be boring. We need to address and take care of the needs for the above nuances. What techniques/enhancement would you recommend for any of these needs? :)
This paper can be a good starting point.