Introduction to SolrCloud
Solr is a well known search engine which launched SolrCloud to deploy and maintain solr on cluster. As distributed application with scale requires multiple solr nodes, this is a big upgrade in solr clustering.
Before Solr 4.x the application had to setup and maintain nodes with cores of shards and replica, in order to maintain a search engine which is robust, highly available, scalable both vertically & horizontally and easily recoverable.
If there is any distributed application using Solr with multiple SolrCore; the legacy solr configuration, we should consider moving to SolrCloud.
Solr Clustering Before SolrCloud
Before SolrCloud the clustering has to be taken care by the application. Typical solr architecture would look like:
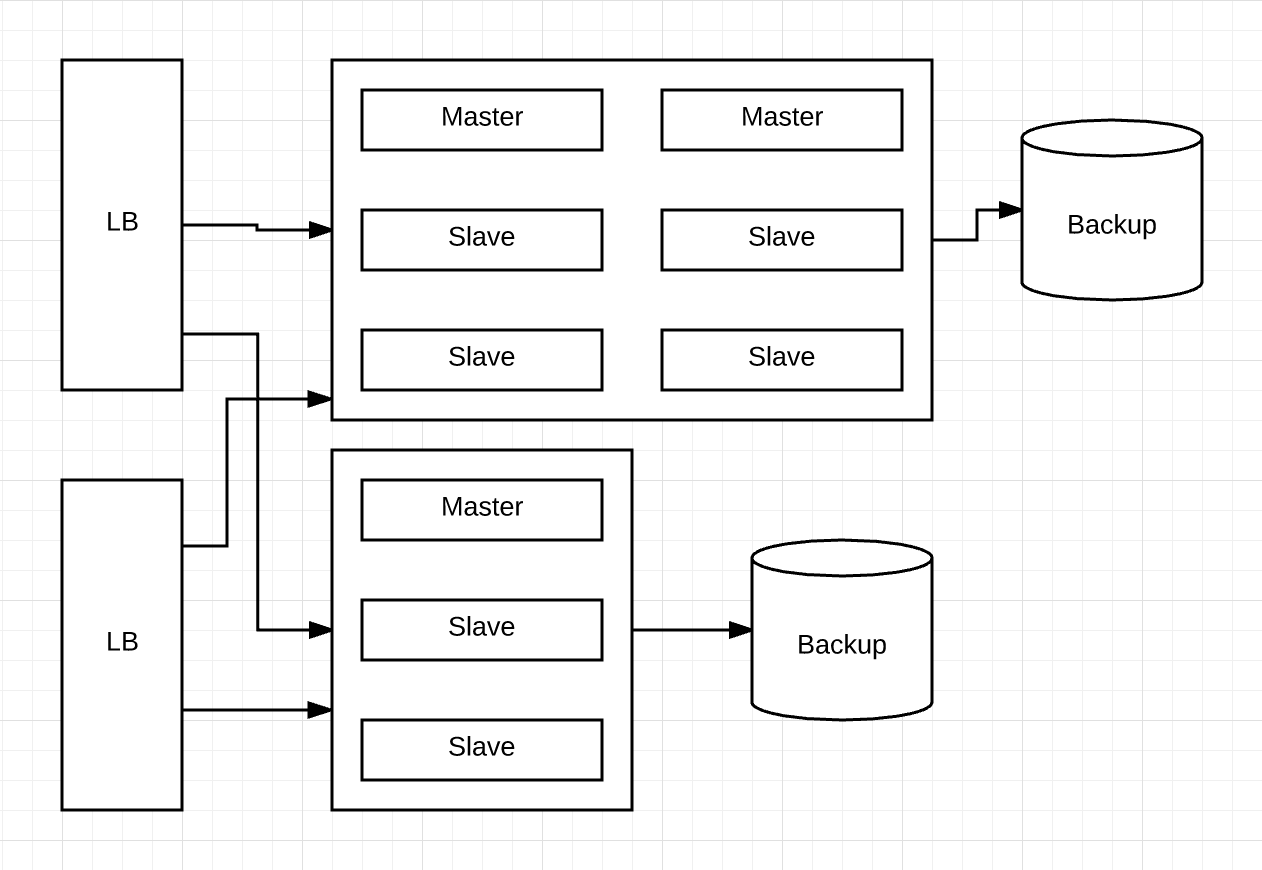
Pain Points of this clustering
- Configuration: Each core on the node has to be configured to act as master or slave. (Slave is a replica of the master, and a master is one shard of the index)
- Custom Routing: the application has to take care which shard to handle write. Application’s load balancer has the overhead of truly distributing the data. Solr couldn’t figure out on its own what shards to send documents to.
- Whenever the shard becomes big we have to manually Split the index
- Failover: Application need to figure which shard to send query to. if one of the shards died it was just gone.
- Monitoring solr: To monitor and analyze the load and performance of Solr, we have to monitor each node in order to figure if it is functioning ok.
Solr Clustering with SolrCloud
SolrCloud introduced fixes for all above pain points. It supports both indexing and querying in true distributed nature. SolrCloud uses ZooKeeper to provide fail over and automatic load balancing. (Of course, we can provide our own custom routing if we want in SolrCloud)
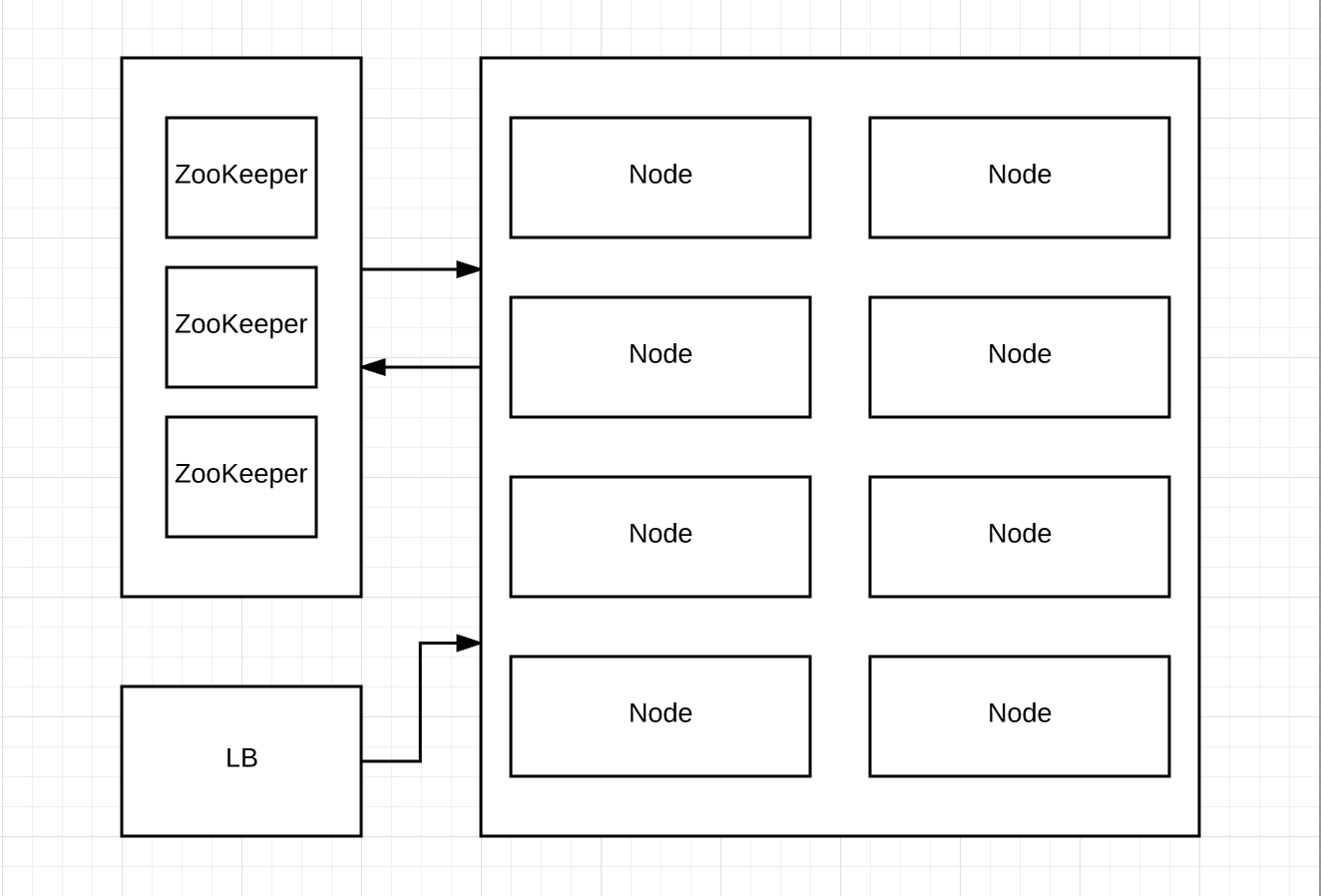
Benefits of SolrCloud
- Centralized configuration: All the config stays in Zookeeper. Whenever any changes are required in
schema.xmlwe need to maintain only at Zookeeper and the nodes will get from ZK. - Node: All Solr servers in the cluster are nodes. In SolrCloud there are no masters or slaves. Every shard consists of at least one physical replica, exactly one of which is a leader. Leaders are elected automatically of course thanks to the integration with ZooKeeper.
- Disposable nodes: Because Zookeeper is driving the config and traffic the index is still up and running with one of the node goes down or replaced or removed.
- Replication: Peer replication - makes it more robust and faster in recovery.
- Collection: SolrCloud introduced collection. Which abstracts out the index and all its cores. Gives easy configuration.
Collection API
Every index in SolrCloud is now called Collection. One index represents one collection. It represents set of cores each are having identical configurations. Union of these cores covers the entire index.
Jargon in SolrCloud
The conceptual Jargon used in SolrCloud with their hierarchy:
| Jargon | Detail | parameter |
|---|---|---|
| Node | Physical machine. Scaling factor for cluster size. Each Node can host multiple Cores. | liveNodes |
| Core | One core of the index. Set of records. A replica. Scaling factor for query per second | replicationFactor |
| Shard | Set of cores. One shard of the index. It can have multiple replica. Scaling factor for collection size. | numShards |
| Collection | Set of shards. Represents one index. Abstraction level of interactions & configurations |
SolrCloud has introduced Collection APIs for creating index and managing the shards and its replicas. SolrCloud handles the hard job of distributing the cores to the appropriate nodes. The APIs makes it easy to configure the index in SolrCloud.
Distributed Requests
Requests can be sent to any node of the cluster and the node with ask Zookeeper which node can handle that request and appropriate node will take it and we will get the response. This way any node is master for the application for the request.